Problem Set Theory
let's learn about these here subsets!


Now that we have a grasp on what problems are from What is a Problem (202306222324) and aren’t from What Isn't a Problem (202306212318) we can launch into the discussion about how computers solve problems. From our definition of problem, we see that solutions are in reality state transitions. When a problem is present, an entity will expend energy to solve that problem by transitioning to a state where that problem isn’t.
Computers, in that they calculate really, really fast, and have access to immense amounts of data are phenomenal at certain types of state transitions being that they have a lot of available states to visit and they can visit these states nearly instantaneously compared to the time the human brain can transition and trial states.
So, it follows that computers help solve problems for entities through automation. The total problem set (all problems that the total collection of entities suffer from) is filled with problems in what we can call the repeatable set. These problems can be solved for in the same way, over and over. An example would be a simple math formula: a 20% tip for example. You are aware that you need to append 20% to the bill, but you don’t have the patience (speed) or the space on your receipt left over (memory) to compute tip. Later in the book we will discuss how exactly computers do this, and how they have gotten inevitably better at conducting this type of work.
The interaction between a human and a computer then is the relationship of making problem solving more efficient. To the point it can be translated into machine code. To solve a problem a computer completes a machine computable problem. As time has gone on and more foundational problems have been solved in the space of computing, the applicable space of potential problems that can be converted into patterns has also grown, much like using the base to put an art gallery or a movie theater or a cafe. What goes in the space matters little if the ground itself is stable.
This means more people have been able to participate in this communication layer. But not by much! According to the Global Developer Population & Demographic, 2019, only 1/3 of 1% of the global population codes. For example, there were fewer people who were actively able to manage the space between machine code translation to assembly and those who were subject matter experts in auxiliary fields such as construction to animal husbandry. This barrier to entry, financial and mental, is largely responsible for few technical people owning much of the tech landscape in judgment and in absentia. By building general computers and general software, engineers and programmers are able to claim an entire swath of abstract land and choose/enforce how people build anything on top of their architecture.
Problem and Pattern Matching Space
Let’s envision an imaginary set of all possible problems, and call it P. Within this set of problems exists a subset called of the repeatable problems above that we can call R. Repeatable problems can be solved over and over with different inputs and are a direct mapping from input to output. On the other side of the set of P, we have non-repeatable but still computable problems, N. These problems are bespoke and have elements of non computability through judgement and pattern matching in the transition from problem to solution. Once a bespoke problem is understood, it can be automated, but that automation is a single purpose tool that can not be abstracted further. Finally, we have problems that are both non repeatable and non computable in set NN. These problems do not have any state transitions that can be automated, and there is no plausible path that we can see leveraging computability either. Our goal is to understand how many problems exist within each subset. As a general rule:
- problems in R can easily be converted to code
- problems in N can likely be converted to machine code with the help of probability matrices like neural networks
- problems in NN can not be converted into computer code, which has a side effect of meaning that in general they are not reliably solvable in the first place. There is a lattice of randomness involved with this level, sometimes the entire graph shifts and a problem state your on straight up blips into or out of existence.
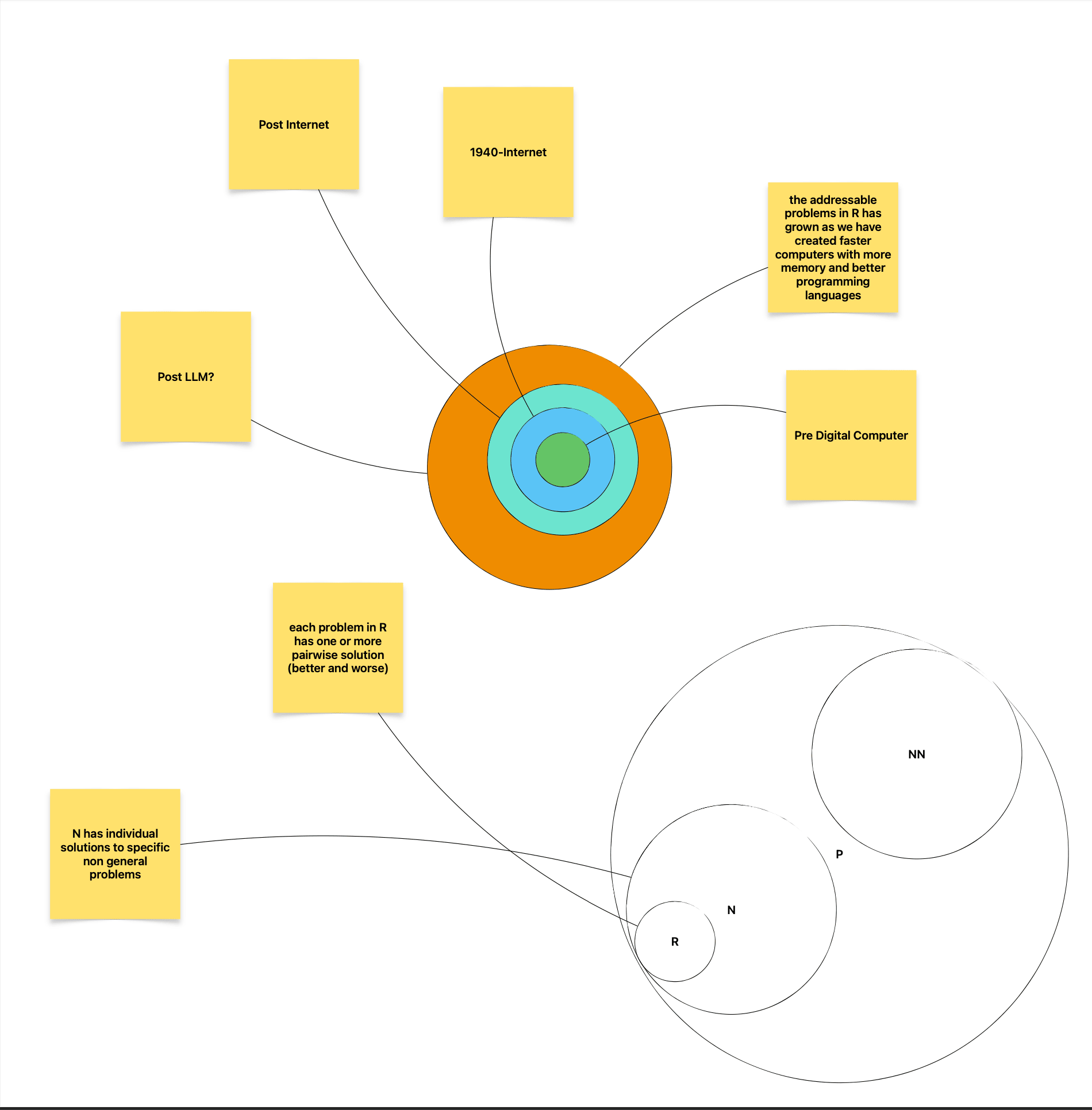
Problems in R
Like the example above, problems in set R are not yet solved, but feel readily solvable using the same tactic.
This distinction is is important. This implies that the problem has a stable solution that moves it to the correct state.
Imagine you step into an imaginary hotel, and the bellhop asks you to follow him. You pick up your bags as he leads you to the elevator. He presses the 10 button, and the elevator begins to ascend. Around floor 5, the evaluator grinds to a halt. You glance nervously at the bellhop but he calmly says there is nothing to worry about as he deftly opens the elevator switchboard and flips wires 2 and 3 in the control panel. The elevator continues to move as if nothing has occurred and your bellhop asks you how your flight was.
In this case, we had a very real problem. We were on floor 5, and desired to be on floor 10. The elevator hit some bug in its code that required a manual override from the bellhop to continue its work. Once the bellhop flipped the wires, the elevator resumed as normal. The lack of emotion on the bellhop’s face implies to us that this is a common state of affairs, and that this elevator is no stranger to this particular malfunction.
Engineered solutions that work are solutions in the R space. How can we make it so the power button turns on/off the computer while the X button applies an X to the screen? We engineer a repeatable solution. If you removed all of the stickers from your keys, each button is functionally the same. We write software that gives them unique, dependable meaning.
Problems in R can be thought of as breadth first search perfected. Instead of grasping for straws and searching randomly, or even relying off gritty heuristics, repeatable problems work every time (or close enough to 100% that it may as well be 100% and errors can be successfully corrected against).
Problems in N
Whereas R was the perfect transition from a state with an existing problem to another state where a problem isn’t, problems in N involve judgement calls.
Let’s return to our imaginary elevator in the imaginary hotel. As the elevator ascends it gets stuck, but the hotel has hired a new bellhop who is unfamiliar with the trick. You glance nervously at him, and he looks back to you also slightly nervous, and chucked “I’m sure it’s fine!” He tries pressing a few buttons, nothing happens. He tries pressing buttons like a piano chord, and the light briefly goes out. Together, you and he open the panel behind the buttons and notice a tangle of wires that seem to have a mind of their own as they are magnetically switching leads. You both realize that one of these sets will be what you need but you aren’t sure which permutations will cause the elevator to move, and which will leave you stuck in place. Eventually after fiddling for a while you find a working configuration, and the elevator continues to quietly ascend. Unfortunately for our new hire bellhop, this exact problem will happen again when he takes the next guest up.
The solution to this problem can’t be automated the way the problem in R were, but we can use patterns and heuristics to narrow our search space. The solution is still engineered in the sense that certain states get us what we desire, the issue Is that the path from problem to solution state dynamically changes, preventing any serious attempt at automation.
Thanks to transformers and LLMs, we are now reaching problem translation where problems can look like very noisy patterns and computers will still be able to match them and solve against them. This allows us to solve problems in this set to great acuity, along with having the flexibility of handling new problems without having to modify any of the underlying code base.
Problems in NN
Finally, we come to problems in the third set, NN. NN is both not computable and not repetitive. Even with an arbitrarily large amount of available compute and sufficient memory, problems in this set cannot be solved with the programming techniques of reliability, and can not be solved with the pattern matching and heuristics of the N set.
The problems in this set have solutions, but the solutions are unreachable by the current scope of technology we have.
Let’s imagine we have tasked all the computers in the world to team up and solve the elevator problem in our imaginary hotel. This includes every cell phone, every smart thermostat up to an including supercomputers at research institutions and server farms at Amazon, Google, etc. The computers run nearly infinite simulations of the combination of passenger weight plus the wiring of the elevator panel. The computers unit test every single possible state that the elevator should (or could) possibly be in. The machine learning models run epochs upon epochs of generations to understand the elevator, and to create a giant matrix that in theory should be able to fix the elevator >95% of the time.
In addition, we recruit all humans with different backgrounds to spend an entire year of humanity focused on this singular problem, with the aim of coming up with novel and creative potential solutions to the buggy elevator. The physicists naturally go after the set of electrons running through the wires. The lawyers research the patents that the elevator was built under, and what jurisdiction has ownership. The dentists examine the teeth of the bellhop, running X-Rays to see if the bellhop has any potential cavities. Schoolchildren go into the elevator and press buttons at random, trying to come up with a funny combo.
Despite all the angles of effort, the problem seems unsolvable. And then suddenly, one day as if by magic, the elevator fixes itself. That’s frustrating! What does this mean?
Problems in the NN set can only be solved by the other nodes outside of the problem set moving the state into the solution. You may call this fate, coincidence, or just plain dumb luck. When creativity and computation cannot force state manipulation despite energy expenditure, sometimes the graph itself needs to change shape.
Multiple Set Problems
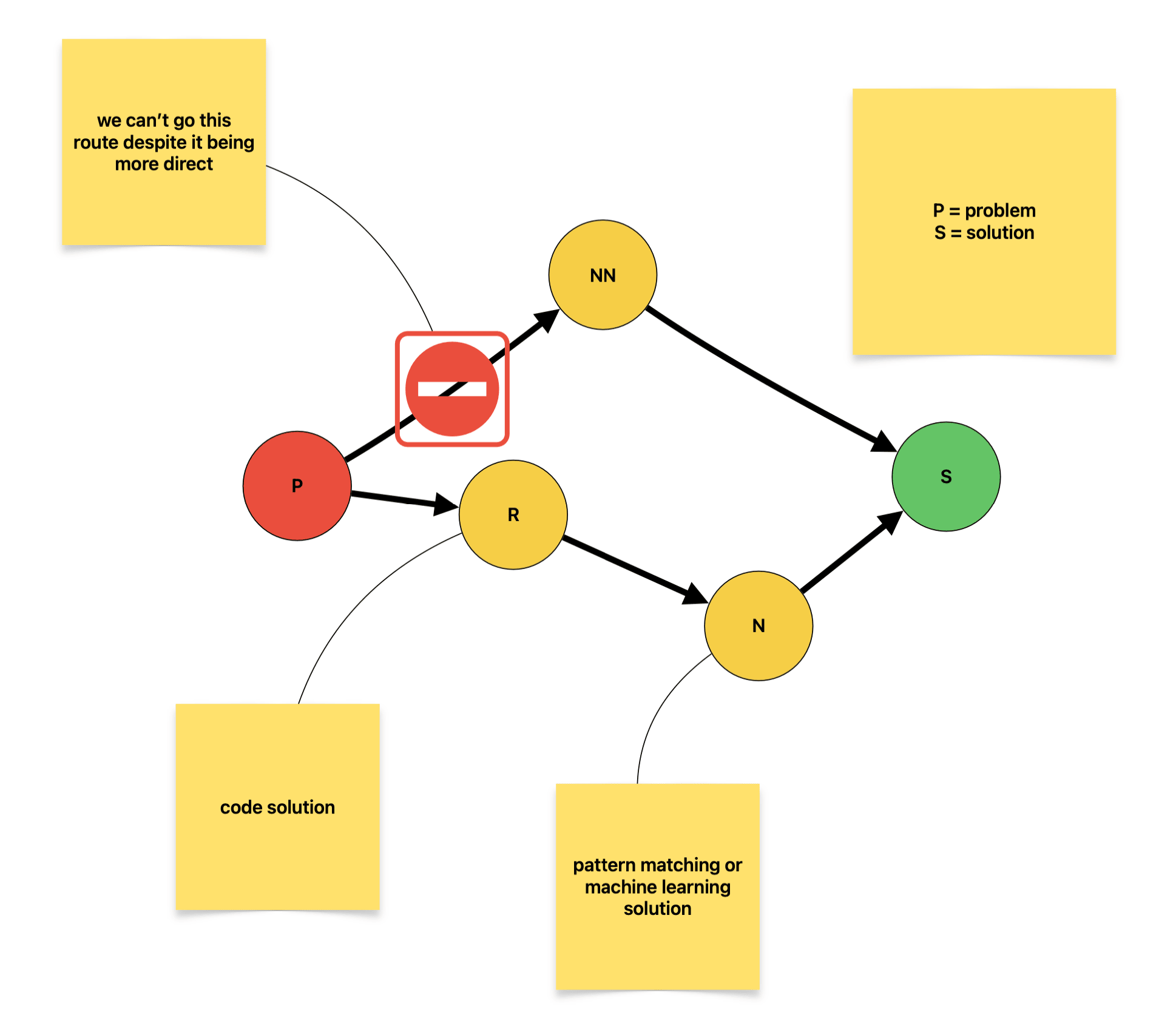
Problems can exist within multiple sets at once. Some NN problems have sub problems in R and subproblems in NN. Subproblems will be discussed later, but problems can well have multiple routes, some of which are completely closed off by a subproblem in NN!
bramadams.dev is a reader-supported published Zettelkasten. Both free and paid subscriptions are available. If you want to support my work, the best way is by taking out a paid subscription.

